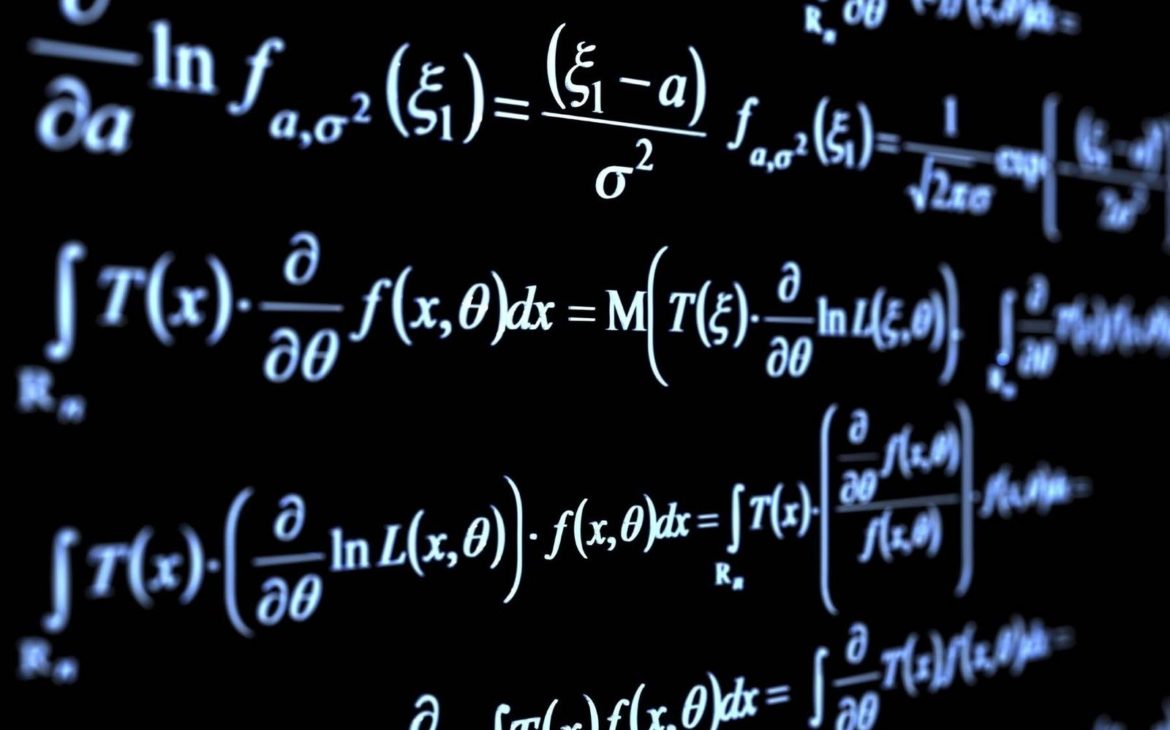
We frequently discuss how data analytics tools can help businesses gain the insights they need to improve their operations. However, we rarely look at the modeling tools used by data analysts to break down data and provide actionable insights. There are various modeling strategies available to an analyst, but for the sake of time, we’ll simply go over the most important data science modeling methodologies, as well as some vital data analysis advice. Here, we are going to discuss the Modeling techniques used by data scientists.
Data analysts employ a variety of data science modeling methodologies, including the following:
Linear Regression
A data science modeling technique called linear regression predicts a target variable. This function is completed by determining the “best” relationship between the independent and dependent variables. The sum of all the distances between the shape and the actual observation should be modest in the resulting graph. The shorter the distance between the points in question, the less likely a mistake will occur.
Simple linear regression and multiple linear regression are the two forms of linear regression. The former uses a single independent variable to predict the dependent variable. Meanwhile, the latter employs the best linear relationship possible to predict the dependent variable by combining numerous independent factors.
Non-Linear Models
Non-linear models are a type of regression analysis that uses observational data and a function to model it. It is a nonlinear model parameter combination that is reliant on one or more independent variables. When dealing with non-linear models, data analysts frequently use a variety of approaches. In data analysis, tools such as the step function, piecewise function, spline, and generalized additive model are all essential.
Supported Vector Machine (SVM)
Supported vector machines (SVM) are classification systems used in data science. There is a maximum margin established in this limited optimization problem. This variable, on the other hand, is dependent on the data classification constraints.
Supported vector machines classify data points by finding a hyperplane in an N-dimensional space. Although any number of planes might be used to separate data points, the goal is to find the hyperplane with the shortest distance between them.
Pattern Recognition
You’ve probably heard of pattern recognition in the context of machine learning and AI, but what exactly does it imply? Pattern recognition is a technology-assisted procedure that compares incoming input to information recorded in a database.
The finding of patterns within the data is the goal of this data science modeling technique. Because pattern recognition is a subclass of machine learning, it differs from the latter.
Pattern recognition is sometimes divided into two stages. The first phase is exploratory, in which the algorithms explore patterns without specifying any criteria. Meanwhile, the algorithms categorize the discovered patterns in the descriptive section. Any sort of data, including words, sounds, and sentiment, can be analyzed using pattern recognition.
Resampling
Data science modeling strategies that include obtaining a data sample and pulling repeated samples from it are known as resampling methods. Resampling creates a unique sampling distribution, which can be useful in analysis. To develop a unique sampling distribution, the technique employs experiential methods. As a result of this technique, unbiased samples of all possible outcomes of the data analyzed are generated.
Bootstrapping
Bootstrapping is a data science modeling technique that can be used in a variety of situations, such as testing the performance of a prediction model. The method works by replacing specific data points that aren’t used as test cases with a substitute from the original data. An approach called cross-validation, on the other hand, is a strategy for validating model performance. It operates by dividing the training data into multiple sections.
Must Read : Popular Machine Learning Algorithms used by Data Scientists