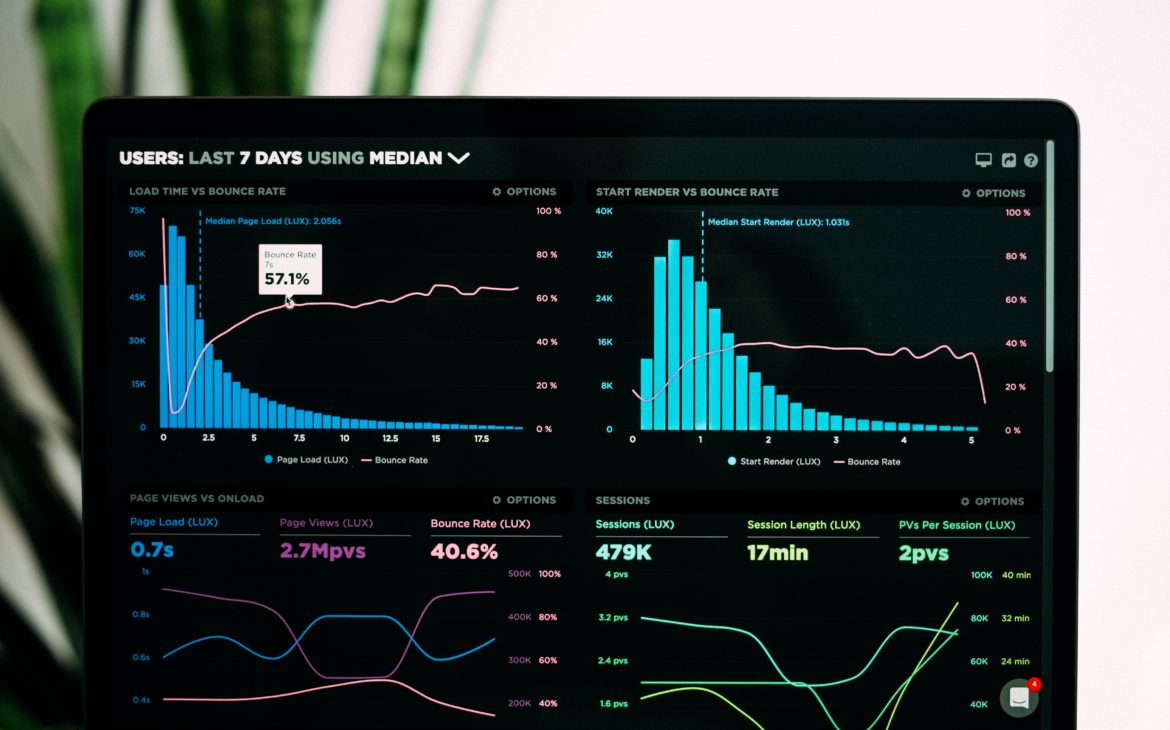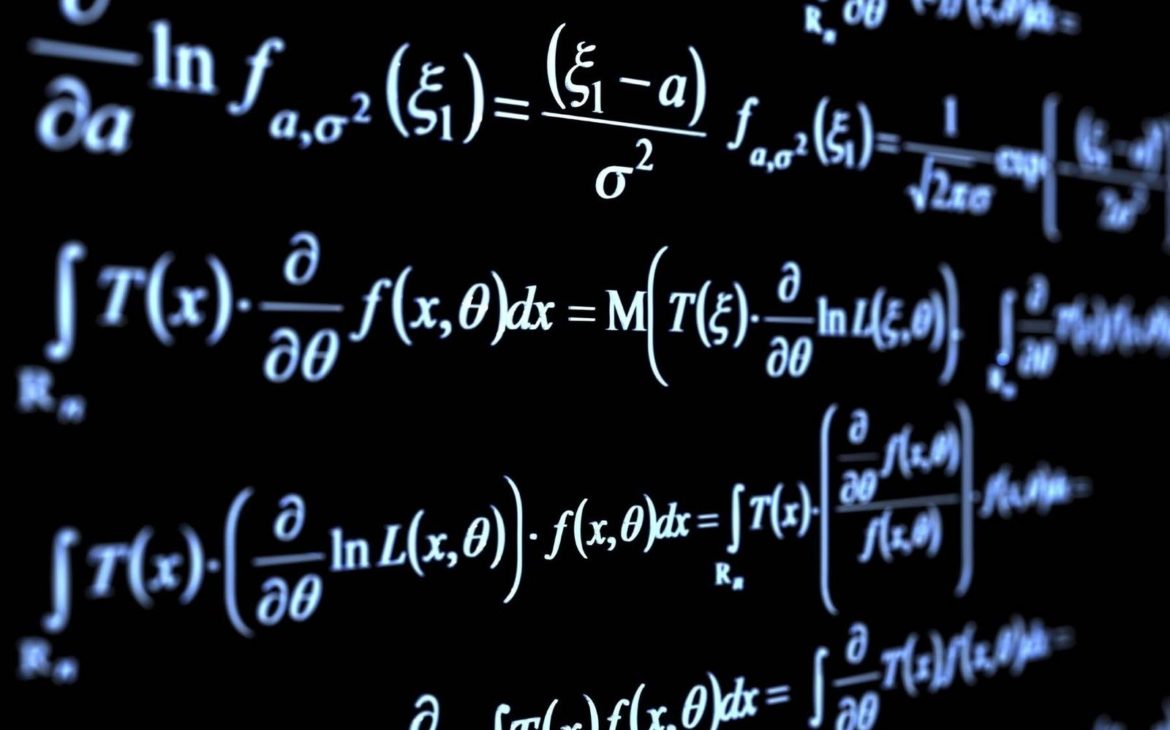
Data scientists might work practically in any field, one thing they all have in common is a basic understanding of mathematics. Math is at the center of everything they do, whether it’s statistics, data analysis, or machine learning. So, let me make you meet the basic mathematical knowledge required for data science.
Arithmetic
Arithmetic, the math we learn in school, is the foundation for practically all other mathematics and is required for data science. The study of numbers and what we do with them, such as addition, subtraction, multiplication, and division, is known as arithmetic.
The dynamics of binary search algorithms are based on logarithms, which are a part of mathematics. A logarithm, in its most basic form, is a little number that lies above another number to denote how many times that number has been multiplied by itself.
A binary search algorithm uses logarithms to search quicker if the data is sorted. As a result, rather than looking at a million items one by one, it can do the same operation in 20 steps or less.
Debugging with a binary search algorithm is a significant tool in programming. Instead of reading over vast portions of code, once the program is built, the algorithm can immediately locate the location where a bug occurs.
Linear Algebra
This branch of mathematics deals with linear equations, vector spaces, and matrices (matrix plural). Linear algebra is a supercharged version of arithmetic that may be used in geometry, physics, and engineering. Matrix algebra is the most important math for data science.
Matrix algebra is used as algebra power. “Anything from friend suggestions on Facebook to music recommendations on Spotify to transferring your selfie to a Salvador Dali-style painting using deep transfer learning,” according to data science author Tirthajyoti Sarkar.
Neural networks, which are machine learning models inspired by the human brain, are likewise powered by the matrix.
Scientists in the United States have recently improved the identification of molecular gases by using neural networks. This application could be utilized in the future to discover unknown chemicals in airport security or to eliminate contaminants in medicine manufacture.
Geometry
You have some knowledge of geometry if you’ve ever used a protractor, compass, or set square. It is the measuring of lengths, areas, and volumes to determine the shape, size, and relative placements of objects.
Some of the theorems in geometry may be familiar to you, such as that all right angles are equal or that the shortest distance between any two points is a straight line. Euclidean geometry builds on high school geometry by extending the concept of measuring distance between objects to the calculating distance between data.
The K-means clustering algorithm, commonly known as Lloyd’s algorithm, uses these measurements. Unsupervised machine learning refers to the K-Means clustering algorithm, which may work with faulty or missing data.
In healthcare, this technique is used to detect structure in unlabeled data in order to produce better patient forecasts. It has also been used to better correctly grade hospitals based on patient comments.
Calculus
We must be careful not to go off on a tangent at this point. Calculus is the study of continuous change, and it evaluates the rate of change in a curve’s slope as well as the area beneath it.
At any point along a curve, a tangent is the best straight-line approximation. Working with regression analysis in statistics requires a thorough understanding of the relationship between tangents and curves.
The linear regression procedure is used to describe the relationship between numerous continuous variables, and this method of statistical modeling sits behind it.
In human resources research, a linear regression technique was employed to determine whether or not a procedure could produce innovation. Researchers looked examined data from 154 businesses that used Spigit, a social media-style innovation aggregator.
Probability
What are the chances that after reading this blog, you will enroll in an online Master of Data Science program? Probability is a numerical value between 0 and 1 given as a fraction or percentage. One of the most basic concepts in statistics is a probability, which is defined as the number of desired outcomes (X) divided by the total number of possible outcomes (T).
The same calculation can be repeated as part of a decision tree to produce far more precise results. In sports, decision tree algorithms have been applied to improve athletes’ performance in a variety of situations.
Bayes Theorem
The Bayes Theorem, which comes into play when you have previously calculated probabilities, is another piece of statistics that is fundamental math for data science. The Naive Bayes’ Classifiers are a set of algorithms based on the Bayes Theorem that uses what we currently know to forecast the likelihood of something occurring. Nave Bayes’ Classifiers are being used alongside other plugins for very detailed DNA research, in addition to medical applications.
Read More : Modeling techniques used by data scientists